Sportwire uses plug-ins for selecting the input feed and for the pre-processing of the input documents. Input feeds are selected through the wirefeeder.feedclass property and control the connection to the feed and how to partition a feed into discreet story blocks. To free the input pipe a quickly as possible (and avoid any backlog in the input buffers), feed XML is queued as text blocks (one per story), with a number of worker threads set on the queue to parse, pre-process and store the documents. The overall process is illustrated in Figure 1
Figure 1. Data acquisition flow diagram illustrating the transformations from ascii/xml to website presentation.
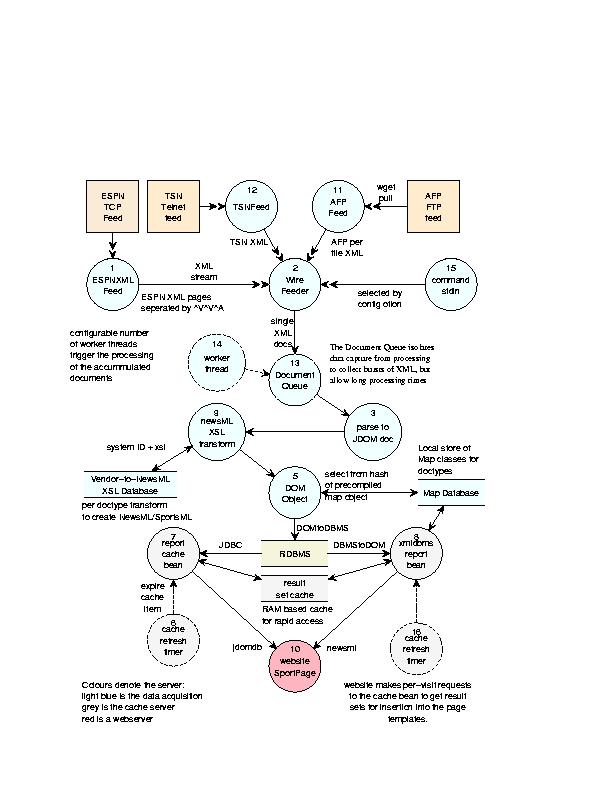
Input feed classes must provide a Reader over each single story. As each story is read, the text XML is tagged with an ID handle (used for debug reporting, most often derived from the DTD) and paired with a document handler before being queued. Document handlers allow alternatives in how the individual documents are parsed and entered into the database and let us ‘pipeline’ the processing. For example, the ToNewsMLFilter applies an XSL transform on the input feed returning a new NewsML document to the queue, the JDOMToFile will render the document XML out to a filename (extracted from the content attribute XPath specified in the config file) while the XMLDBMSDocHandler selects an XMLDBMS Map schema for object-relational mapping and stores the document to the database.
Data acquisition must trap incoming text streams with zero loss, and translate the feed XML to the standard NewsML format used in the backend system. Here's how the process works:
The feed arrives over the socket, it is read in as text and chopped at the end of each message. At this stage, we do simple line-by-line text regex pattern matches and substitutions, irrespective of any XML, trap potential CDATA sections, and route potential pre-formatted text out to an external txt2html™ process.
Each message chunk is tagged, paired with a ToNewsMLFilter document handler and queued.
The worker parses the contents into a JDOM object and extracts the DOCTYPE system ID as an indentifier.
This ID is matched to a NewsML transformation stylesheet of the same name, for example scoresxml.dtd will hunt down scoresxml.xsl. This produces a new JDOM object conforming to the NewsML DTD, and this new object is again tagged, paired with a JDOMToFile or XMLDBMSHandler and re-queued.
The JDOMToFile handler extracts a filename from the NewsML document (according to a config property XPath) and writes the object out as XML; the XMLDBMSDocHandler uses the SystemID to match to an XMLDBMS Object:Relationl Map spec file and uses this to post the contents to the database.
To remain flexible to new document types, the transformation from vendor-feed to NewsML is left to the XSL stylesheets. Ensuring the integrity of the transform result is the responsibility of the XSL author.
Although we have a Java-based representation of a feed-specific Document object in 3, that module has no knowledge of feed-specific rules or structure, so any modifications made through Java calls would have to be generic. In 5, however, we know we have a NewsML object, so we could inspect it, extend it or correct any flagged fields, for example, to change league names or lookup numerical ID values.
The input feed requires contains preprocessing before it can be parsed using the Java tools[1]; parsing at this stage must be done using brute-force methods such as perl regular expressions.
The illustration in Figure 2 shows the initial read process for the SportsNetwork TSNFeed feed handler:
The connection is managed by an instance of the ORO TelnetClient (1) set with a timeout watch thread (2) to abort the feed process if the connection is lost (WireFeeder will attempt to reconnect).
Each line read is added to a storybuffer; element contents are escaped to protect against common HTML entities
“Long” element text is most often preformatted ASCII text. These lines are collected in a CDATA buffer; when the reader detects the end of the element, the CDATA buffer is sent to an external txt2html™ process and the resulting HTML added to the storybuffer, protected with CDATA tags.
When the feed reader detects the “end of story” tag, storybuffer is returned to the WireFeeder as a StringReader.
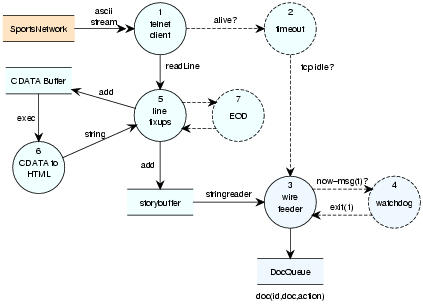
Vendor format XML entered in the document queue is paired with a document handler; in the case of the SportsNetwork feed, we have paired this with the ToNewsMLFilter handler which will transform the vendor format into the standard IPTC SportsML format.
The illustration in Figure 3 shows the transformation process:
The received XML is parsed into a JDOM instance.
The doctag (the systemID) is used to locate an XSL file which is applied to the JDOM; the resulting JDOM is then re-queued paired with the JDOMToFile handler.
JDOMToFile extracts a filename from the XML object and serializes the object out to that file.
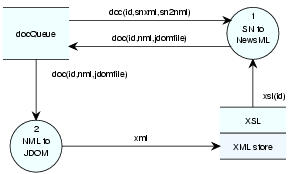
Adding support for a new XML document requires the table(s) in the RDBMS (for document handlers requiring database storage), an XSLT specification transforming the document to NewsML, and a Map file to correspond to the generated NewsML DocType system identifier. On the webserver side, database result sets may be obtained using standard access technologies (JDBC, ODBC &c) or by calling the XMLDBMS DBMStoDOM to retrieve the NewsML as a JDOM or W3C Document object.
News messages arrive in bursts; in the FTP delivery, or when stories are added at the command line, documents may arrive as fast as the program can read them. Parsing and database mapping, on the other hand, takes significant time; just parsing one XML file through xerces takes more time than reading 18 consecutive stories through stdin.
Sportwire uses a task-queue/worker system to buffer input; incoming character streams are segmented into document objects that are added to a thread-safe FIFO queue, and a fixed number of worker threads read this queue and process the documents.
The DocQueue is type-agnostic; the queue is a singleton object (to reduce any risk of collisions or resource runaway conditions) which queues DocQueueElement items, and each worker thread simply pops the last item from the list and passes it to the DocHandler. In the case of the XMLDBMSDocHandler, the objects are assumed to have the XML contents available through the toString() method. Document handlers may use whatever methods they wish to extract the XML.
After the end of the input, or on a critical failure in the input parsing, Sportwire alerts the DocQueue to complete the processing of all pending document documents and then exit; for this reason, a SIGTERM signal may take a few minutes to shut down; SIGKILL will cause all pending documents to be lost.
Sportwire is only concerned with the parsing and archiving of XML data streams. In many applications, the actual interface may be via FTP or through the Sportsticker dedicated line. In these situations, data is pre-processed through a chain of applications before entering the Sportwire system.
Example 1. Input Pipeline on the Legacy Sportsticker
To process the legacy (pre-2002) Sportsticker, the input stream passes through the following pipeline:
The Sportsticker modem is connected through the serial port; the included Compat/Broadcaster application reads this feed and relays the input across a TCP/IP or unix socket. Multiple applications can then access this feed by connecting to the broadcast port (default: port 4045).
The legacy feed is delimited by binary codes in an ASCII stream; the Compat/Wire2XML application translates these codes into the OLD*.dtd XML formats, reading from a file, stdin or from a socket, and writing the XML output to stdout.
Wire2XML output is fed into the Java ca.cbc.sportwire.Feeder application; properties are set to use the ESPNFeeder input parser to speperate the incoming stream into documents on the Sportsticker ^V^V^A boundary markers.
[1] The vendors claim their XML will parse, and SportsNetwork claims (in private emails from BJ) that their feed is generated with XML tools, yet their feed contains no charset declaration, and entities and attributes often contain ampersands (&), backquotes and other characters not allowed by the Xalan/Xerces suite of XML parsing tools. Whether this is a flaw in their XML generating tools or a flaw in the apache parsers is unknown. Clarification is welcome.